[NLP]Word2vec
1. Word2vec
- Tomas Mikolov가 2013년 처음으로 소개한, 단어를 벡터로 변환하는 방법론을 제시한 모델 간단한 신경망을 사용했기만 성능이 뛰어나 각광받음
- Word2vec 논문 링크
- 기존의 one-hot encoding은 매우 직관적인 벡터화 방법이지만, 다양한 문제점을 가지고 있다.
- 구분해야하는 단어나 데이터의 양이 많아지면 공간적인 부분의 차지가 많아져 비효율적이다.
- 의미적으로 유사한 단어끼리의 유사도 표현이 불가능하다.
- One-hot encoding의 유사도의 측정이 어려운 점을 보완하기 위해 분산표현(Distrivuted Representation)을 제시했다.(기존의 0과 1만으로 표현하는 것 대신 실수의 형태로 대상을 나타내기 시작했다.)
1. 분포가설
- 위의 분산 표현을 지지하기 위해서는 분포 가설이 뒷받침 되어주어야 한다.
- 분포가설은 언어학자인 젤리그 해리스(Zelling Harris)가 주장한 내용이다. 그는 “같은 맥락에서 등장하는 단어들은 비슷한 의미를 가지는 경향이 있다.”라 주장했고, 이는 즉, 한 문장에서 많은 빈도로 사용되는 문장은 맥락이 비슷하다면 같게 등장할 것이라는 이야기이다.
- 예시) 나는 철수의 집에서 밥을(먹었다., 세웠다.) 문장에서 뒤에 올 알맞은 내용을 고른다면 당연하게도 ‘먹었다’일 것이다. 이와 유사한 맥락을 가지는 밥, 바나나, 키위 등 음식이라는 카테고리 안에서는 같은 내용을 선택하게 되는 경향이 있다는 것이다.
2. 그렇다면?
-
위의 one-hot encoding을 보완하는데 분산 표현을 제시하였고, 이 분산표현은 분포가설에 기반하며, 이를 구현한것이 Word2vec이라는 것이다.
-
단 한 층으로 위의 내용들을 구현해낸 것이다!

- 위는 Word2vec을 구현하는 두가지 방법인 CBOW(Countinuous bag-of-word)와 Skip-gram을 나타낸 것이다.
1. CBOW(Countinuous bag-of-word)
- 주변의 단어들로부터 중심단어가 나올 확률을 학습한다.
2. Skip-gram
- 중심단어가 나왔을 때 주변 단어가 나올 확률을 학습한다.
3. Word2vec 사용 방법
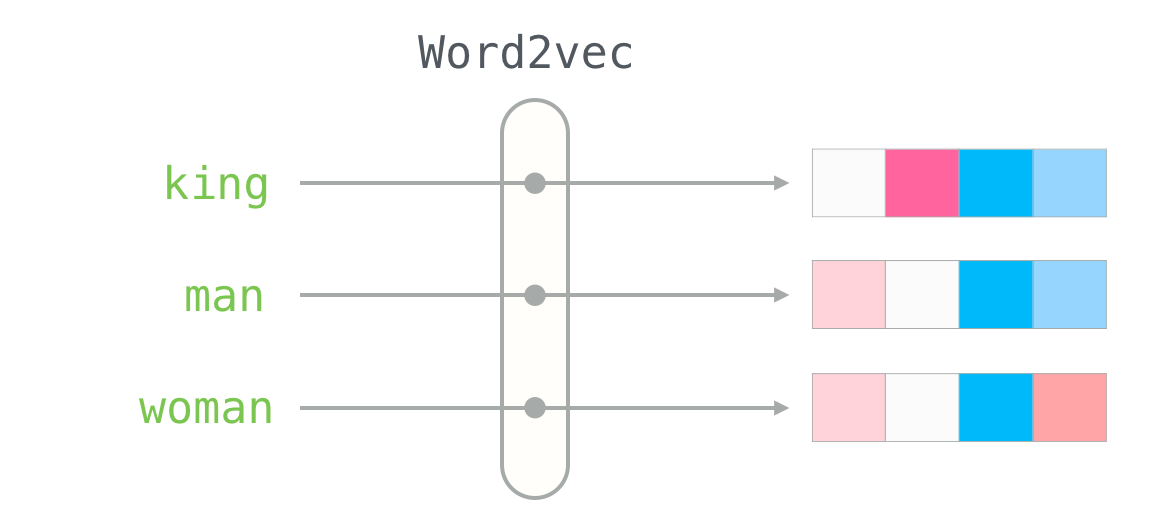
- 위의 그림은 Word2vec의 원리에 대해 설명하고 있다.
- 위의 CBOW와 Skip-gram은 인코더와 디코더로 구성되어있는데 여기서 ‘인코더’만 사용하는 것이다.
- 원하는 단어를 Input으로 사용했던 One-hot vector로 변경한다.(vocab에 없던 단어가 나오면
에 매핑) - 이후 단어 벡터와 W를 곱한다.
- W에 있는 해당 단어의 벡터가 나오게 된다.
- 원하는 단어를 Input으로 사용했던 One-hot vector로 변경한다.(vocab에 없던 단어가 나오면

- 계산을 살펴보면 다음과 같다.
- 위의 이미지에서 결국 집어넣은 단어의 1이 존재하는 곳과 연산이 이루어지는 부분만을 최종 출력으로 갖는다. 이처럼 원하는 최종 출력물을 뽑아서 보는 것을 ‘lookup’이라고 한다.
2. Word2vec의 활용과 문제점
1. 활용
-
영문에 기반하는 데이터에서 좋은 성능을 보여준다.
-
또한 기계번역에서 번역에 사용할 수 있음
2. 문제점
- Imbalance Overhead의 문제점을 가짐
- 디코더의 과정에서의 엄청난 수의 연산과정문제가 발생함
- 토큰이 8400억개 단어가 220만개 Embedding차원이 300개 연산이 6.6억번 반복되어 최종적으로 소프트맥스를 거쳐 결과물로 출력되는데 매번 저 연산과정을 반복해야한다.
- 디코더의 과정에서의 엄청난 수의 연산과정문제가 발생함
3. 해결방안?(개선점)
Negative sampling
- 매 스텝마다 모든 행렬을 다 계산하지 않고, 몇 개의 샘플을 뽑아 계산하는 방식으로 연산량을 감소시킴
- 실제 정답(Positive sample)과 몇 개의 오답(Negative sample)을 대상으로 계산
-
연산량이 획기적으로 감소함
- 샘플을 뽑는 기준
- 학습 데이터셋이 작을 경우 5~20개, 크기가 클 경우 2~5개
- Negative sample을 뽑는 방법
- 단어의 빈도수를 파악하고 이를 특정 계산식을 통해 선출
-

Subsampling
- NLP관점에서 많이 나온 단어는 중요한 단어로 취급한다.
- Wrod2vec에서도 많이 나오는 단어는 그만큼 학습에 그대로 사용한다. 하지만 많이 나온 단어가 정말 중요한 경우가 아닐 수 있음 (이전의 stop words를 제거하는것과 비슷함)이를 배제하는 방법(이 방법 역시 단어의 빈도수를 활용한다.)
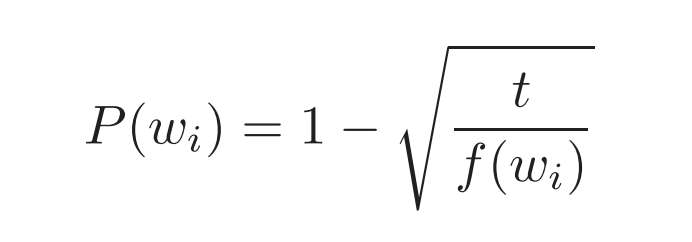
출처 : https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/ https://jalammar.github.io/illustrated-word2vec/ https://excelsior-cjh.tistory.com/156 https://wikidocs.net/22660
Leave a comment