[NLP]데이터 전처리와 인코딩 그리고 코사인 유사도
1. 전처리 기법
1. 토큰화(Tokenize)
- 문장을 token으로 잘라주는 과정
- Token : 어휘 분석의 단위 주로 단어를 Token 단위로 사용한다.
- 예시 ) My birthday is May 5 -> [‘My’, ‘birthday’, ‘is’, ‘May’, ‘5’]
2. Stop Word 제거
- 이전 시간에도 다뤘었다. 높은 빈도로 등장하지만 분석에 큰 비중이 있지 않는 단어를 말한다.
- 예시 ) the, in, a 등의 관사는 자주 등장하지만 의미가 없다.

3. 형태소 분석(Stemming)
- 형태소를 분석하여 단어의 핵심적인 뜻 부분만을 추출하는 과정
|  |
2. 데이터 인코딩
1. 원-핫 인코딩(One- hot encoding)
- 단어를 컴퓨터가 이해할 수 있도록 단어를 0과 1로 표현하는 방법
- [단어개수]X[단어개수]인 행렬 생성
- 해당 단어의 위치만 1로 바꾸어줌
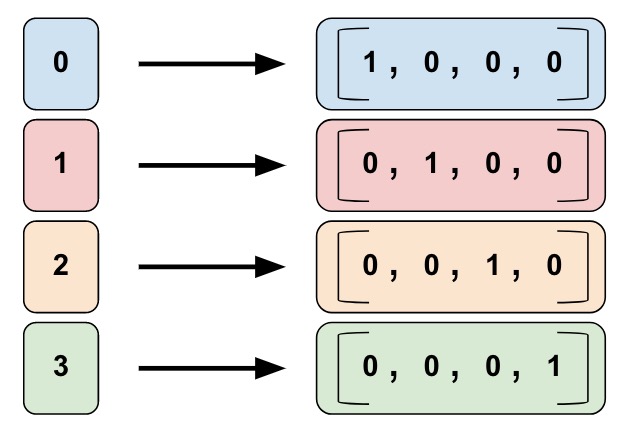
- 위의 이미지를 살펴보면 0은 [1,0,0,0] 1은 [0,1,0,0]등 각각을 0과 1로 표현한다.
3. 코사인 유사도(Cosine Similarity)
- 단어나 문장의 유사도를 표혆라는 방법 중 하나
- 단어나 문장을 벡터로 표현했을 때, 두 벡터의 사잇각을 이용하여 구한다.
![Cosine similarity - Statistics for Machine Learning [Book]](https://www.oreilly.com/library/view/statistics-for-machine/9781788295758/assets/2b4a7a82-ad4c-4b2a-b808-e423a334de6f.png)
-
위의 그림에서 item2와 item1의 사잇각이 가까워질수록 유사도가 강하고, 각이 커질수록 유사도가 낮아지는 것을 가지고 각각의 유사도 판별이 가능하다. 수식은 아래와 같다.
-
위의 원핫 인코딩을 수행한 문장을 가지고 코사인 유사도를 통해 각 문장간의 유사한 정도를 측정하는데 이용할 수 있다.

Leave a comment